واقعیت این است که فقط آدمها از سایت شما بازدید نمیکنند. تعجب نکنید! رباتهایی هم وجود دارند که در روز بارها و بارها به صفحات وبسایت شما سر میزنند و هر کدام هم وظیفهای دارند. مثلا ربات گوگل کارش این است که صفحات جدید در اینترنت را پیدا کند. این کار به ایندکس شدن این صفحات در گوگل کمک میکند و افراد میتوانند آن صفحات را ببینند.
در واقع اگر این رباتها نباشند، صفحات ارزشمند سایت شما که برای تولید آنها خیلی زحمت کشیدهاید، اصلا روی بستر اینترنت دیده نمیشوند. اما از آنجا که این رباتها ممکن است برخی چیزهایی که ما دوست نداریم را به دیگران نشان بدهند، برای کنترل کردنشان نیاز داریم تا با زبان رباتی با آنها حرف بزنیم. فایل robots.txt همان بستری است که کمک میکند تا رباتها زبان ما بفهمند.
Robots.txt یک فایل متنی است و برای رباتهای خزندهای که برای بررسی یا کارهای دیگر به وبسایت شما سر میزنند، نقش راهنما را بازی میکند.
فایل robots.txt بخشی از پروتکل REF یا robots exclusion protocol است، گروهی از استانداردهای وب که نحوه کرال کردن رباتها و همچنین دسترسی و ایندکس کردن محتوای صفحات توسط رباتها را تنظیم میکنند و این محتوا را به کاربران ارائه میدهند. لینکهای فالو و نوفالو نیز بخشی از پروتکل REP هستند.
فایل robots.txt را وبمسترها میسازند و با این فایل به رباتها دستور میدهند که چه صفحاتی را کرال یا ایندکس کنند و در چه صفحاتی نباید وارد شوند. در عمل، فایل robots.txt نشان میدهد که آیا برخی از نرمافزارهای کرال کردن وب میتوانند قسمتهایی از یک وبسایت را کرال کنند یا خیر. این دستورالعملها با «disallow» یا «allow» مشخص میشوند.
اصلا دستور دادن به رباتها چه فایدهای دارد؟ مگر اشکالی دارد که رباتها همینطور برای خودشان در وبسایت ما بچرند؟ بله. اشکال دارد! اگر رباتها را کنترل نکنید، سرور هاست سایت شما درگیر رباتهایی میشود که فایدهای برای سایتتان ندارند. همچنین روی بهینهسازی سئوی سایت شما هم تاثیر میگذارد.
فایل robots.txt چیست؟
علاوه بر کاربرانی که از سایت شما بازدید میکنند، رباتهایی هم وجود دارند که در روز بارها و بارها به صفحات سایت شما سر میزنند و هر کدام کاری انجام میدهند. در واقع اگر این رباتها نباشند، صفحات ارزشمند سایت شما اصلا روی بستر اینترنت دیده نمیشوند. اما از آنجایی که این رباتها ممکن است همهچیز را به کاربران نشان دهند، نیاز است دستوراتی برایشان نوشت. فایل robots.txt همان بستری است که کمک میکند تا رباتها زبان ما را بفهمند.
Robots.txt یک فایل متنی است که برای رباتهای خزندهای که سایتتان را بررسی میکنند، نقش راهنما را بازی میکند. این راهنما شامل دستوراتی است که وظایف رباتها را مشخص میکند. اگر فعالیت رباتها کنترل نشود حتی روی سئوی سایتتان نیز تاثیر خواهد گذاشت. در ادامه مقاله با ما همراه باشید تا بیشتر با نحوه عملکرد فایل robots.txt، دستورات آن، نحوه رفع ارورها و به طور کلی دلایل نیاز به robots.txt آشنا شوید.
robots.txt چگونه کار میکند؟
فایل robots.txt مجموعهای از دستورالعملها برای خزندههای وب (رباتها) است. این فایل بخشی از پروتکل استانداردی بهنام REP یا robots exclusion protocol است؛ مجموعهای از قوانین وب که به موتورهای جستجو اعلام میکند به کدام بخشهای سایت اجازه دسترسی دارند و از کدام بخشها باید دوری کنند. این تعامل به مدیریت بهتر نحوه ایندکسشدن صفحات کمک میکند و باعث میشود خزندهها بر بخشهای مهم و مرتبط سایت تمرکز کنند.
موتورهای جستجو برای خزش سایتها، از طریق لینکها به صفحات مختلف دسترسی پیدا میکنند و با دنبالکردن آنها از یک صفحه به صفحه دیگر میروند. به این ترتیب، کل سایت از طریق شبکهای از لینکها خزیده میشود، روشی که به آن خزش عنکبوتی نیز گفته میشود.
زمانی که خزندهای مانند Googlebot وارد یک سایت میشود، ابتدا به دنبال فایل robots.txt در روت دامنه میگردد. اگر این فایل موجود باشد، آن را پیش از خزش سایر صفحات میخواند. از آنجایی که robots.txt میتواند حاوی دستورالعملهایی در مورد مجاز یا غیرمجاز بودن دسترسی به بخشهای مختلف سایت باشد، این اطلاعات مسیر خزش ربات را هدایت میکند.
اگر فایل robots.txt وجود نداشته باشد یا هیچ دستورالعملی برای محدودکردن فعالیت خزندهها در آن ثبت نشده باشد، ربات با فرض مجازبودن خزش، ادامه سایت را بررسی میکند و به خزش سایر بخشها میپردازد.
نکات بیشتر درباره فایل robots.txt
- یک فایل txt باید در top-level directory سایت قرار بگیرد.
- txt نسبت به حروف کوچک و بزرگ حساس است: پرونده باید «robots.txt» نامگذاری شود (نه به شکل Robots.txt، robots.TXT).
- برخی از رباتها ممکن است توجهی به فایل txt شما نکنند. این موضوع مخصوصا در رباتهای مخرب، خیلی زیاد دیده میشود.
- فایل robots.txt بهصورت عمومی در دسترس است: فقط کافیست /robots.txt را به انتهای دامنه اصلی اضافه کنید تا دستورالعملهای آن سایت را ببینید. یعنی هر کسی میتواند ببیند شما چه صفحاتی برای کرالشدن یا نشدن مشخص کردهاید. بنابراین از آن برای مخفیکردن اطلاعات خصوصی کاربر استفاده نکنید.
تفاوت robots.txt با متا تگ noindex چیه؟
فایل robots.txt و متا تگ noindex هر دو برای مدیریت نحوه تعامل موتورهای جستجو با محتوای سایت استفاده میشوند، اما عملکرد و هدف آنها کاملاً متفاوت است.
همانطور که گفتیم فایل robots.txt موتور جستجو را راهنمایی میکند که کدام بخشها و فایلها را باید کرال کند. این فایل باعث نمیشود که محتوا از ایندکس خارج شود یا در نتایج جستجو نشان داده نشود.
متا تگ noindex به موتورهای جستجو میگوید که محتوای مورد نظر را در نتایج جستجو نشان ندهند و اگر این محتوا قبلاً ایندکس شده باشد، باید بهطور کامل آن را از ایندکس خارج کند. این تگ جلوی کرال محتوا را نمیگیرد.
مهمترین تفاوت این دو در این است که اگر میخواهید محتوایی در نتایج جستجو ظاهر نشود، حتماً باید از تگ noindex استفاده کنید و اجازه دهید موتور جستجو آن محتوا را کرال کند. اگر موتور جستجو نتواند محتوایی را کرال کند، نمیتواند تگ متای noindex را ببیند؛ بنابراین نمیتواند آن را از نتایج حذف کند.
اما اگر نمیخواهید موتور جستجو بخشی از سایت را کرال کند (مثلاً دایرکتوریهایی که محتوای مهمی ندارند)، از دستور Disallow در فایل robots.txt استفاده کنید.
آیا ممکن است آدرسی که در robots.txt مسدود شده است، در نتایج جستجو گوگل نمایش داده شود؟
بله، اگر یک صفحه وب با استفاده از فایل robots.txt مسدود شده باشد، آدرس URL آن همچنان میتواند در نتایج جستجو نمایش داده شود، اما نتیجه جستجو فاقد توضیحات (description) خواهد بود.
فایلهای تصویری، ویدئویی، PDF و سایر فایلهای غیر HTML که در آن صفحه مسدودشده قرار دارند، نیز کرال نخواهند شد.
اگر چنین نتیجهای را برای صفحه خود در جستجو مشاهده کردید و میخواهید آن را اصلاح کنید، دستور مربوط به مسدودسازی آن صفحه را از فایل robots.txt حذف کنید. اگر قصد دارید صفحه را بهطور کامل از نتایج جستجو پنهان کنید، باید از روش دیگری استفاده کنید.
میتوانید از فایل robots.txt برای مدیریت ترافیک خزش و همچنین جلوگیری از نمایش فایلهای تصویری، ویدئویی یا صوتی در نتایج جستجوی گوگل استفاده کنید.
توجه داشته باشید که این کار مانع از آن نمیشود که سایر صفحات یا کاربران به فایلهای تصویری، ویدئویی یا صوتی شما لینک دهند.
همچنین میتوانید با استفاده از فایل robots.txt فایلهای منابع مانند تصاویر کماهمیت، اسکریپتها یا فایلهای استایل را مسدود کنید، در صورتی که فکر میکنید نبود این منابع تأثیر قابل توجهی بر نمایش صفحه ندارد.
اما اگر نبود این منابع باعث شود که درک محتوای صفحه برای خزنده گوگل سختتر شود، از مسدودکردن آنها خودداری کنید. چرا که در این صورت، گوگل نمیتواند بهدرستی صفحات وابسته به این منابع را تحلیل کند.
آیا برای هر سابدامین باید فایل robots.txt جداگانه داشته باشد؟
بله، برای هر سابدامین (Subdomain) باید یک فایل robots.txt جداگانه داشته باشید.
گوگل و دیگر موتورهای جستجو هر سابدامین را بهعنوان یک سایت مستقل در نظر میگیرند؛ بنابراین اگر شما سایتهایی مانند blog.example.com یا shop.example.com دارید، باید برای هرکدام فایل robots.txt جداگانه در مسیر اصلی همان سابدامین قرار دهید:
- https://blog.example.com/robots.txt
- https://shop.example.com/robots.txt
اگر فقط فایل robots.txt را در https://example.com/robots.txt قرار دهید، این فایل تنها بر دامنه اصلی تأثیر میگذارد و هیچ اثری بر سابدامینها نخواهد داشت.
پس اگر میخواهید دسترسی خزندهها را برای بخش خاصی از یک سابدامین مدیریت کنید، باید مستقیماً در همان سابدامین فایل robots.txt مربوط به خودش را تعریف و تنظیم کنید.
چگونه در سرچ کنسول صفحاتی که تحت تاثیر فایل robots.txt به ارور خوردهاند را بررسی کنیم؟
برای شناسایی خطاهای مربوط به فایل robots.txt در گوگل سرچ کنسول، مراحل زیر را دنبال کنید:
- وارد حساب گوگل سرچ کنسول خود شوید و property مورد نظر را انتخاب کنید.
- در پنل سمت چپ، زیر تب «Index»، روی گزینهی «Pages» کلیک کنید.
- به پایین صفحه اسکرول کنید تا صفحات دارای خطای ایندکس را ببینید. از میان لیست مشکلات ایندکس، به دنبال خطاهای «Blocked by robots.txt» و «Indexed, though blocked by robots.txt» بگردید.
- روی هرکدام از این خطاها کلیک کنید تا لیستی از URLهایی که تحت تأثیر قرار گرفتهاند نمایش داده شود.
چگونه ارورهای گوگل برای فایل robots.txt را در سرچ کنسول چک کنیم؟
اگر دستورات داخل فایل robots.txt با syntax نادرست نوشته شده باشند (مثلاً اشتباه در نوشتن دستورات User-agent یا Disallow)، گوگل در سرچ کنسول در بخش setting گزینه robots.txt را انتخاب کنید، بر روی آدرس فایل robots.txt سایت خودتان کلیک کنید و گزارشی که در سمت راست صفحه باز میشود را بررسی کنید. اگر دستوری دارای مشکل syntaxی باشد گوگل با نمایش علامتی قرمز رنگ در کنار آن دستور، آن را برای شما مشخص میکند. در صورت مشاهده اخطارها و ارورها، دستورات را اصلاح کرده و سپس درخواست Recrawl فایل را ثبت کنید.
چگونه برای گوگل درخواست کرال مجدد فایل robots.txt ارسال کنیم؟
زمانی که یک خطا را اصلاح کرده یا تغییر مهمی در فایل robots.txt ایجاد کردهاید، میتوانید درخواست کرال مجدد (Request a Recrawl) دهید.
در حالت کلی، نیازی به درخواست کرال مجدد فایل robots.txt ندارید؛ زیرا گوگل بهصورت مکرر این فایل را بررسی میکند.
اما در شرایط زیر، ممکن است بخواهید این کار را انجام دهید:
- قوانین فایل robots.txt را تغییر دادهاید تا برخی از URLهای مهم را از حالت مسدود خارج کنید و میخواهید گوگل سریعتر از این تغییر مطلع شود (توجه داشته باشید که این به معنی کرال مجدد فوری آن URLها نیست).
- خطای واکشی (fetch error) یا خطای مهم دیگری را برطرف کردهاید.
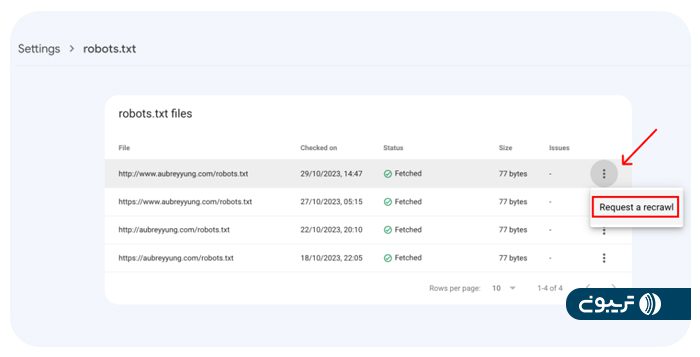
برای درخواست کرال مجدد، از نوار سمت چپ وارد تنظیمات (Setting) شوید، از بخش کرالینگ (crawling) روی Open report برای گزینه robots.txt بزنید و وضعیت و جزئیات گزارش robots.txt را مشاهده کنید.
سپس در فهرست فایلهای robots.txt، روی آیکون تنظیمات بیشتر (More settings) در کنار فایل مورد نظر کلیک کرده و گزینه Request a recrawl را انتخاب کنید.
چه دستوراتی در فایل robots.txt وجود دارد؟
فایلهای robots.txt از دستورهای سادهای برای انتقال پیام به کرالرهای وب استفاده میکنند. صاحبان سایت با استفاده از این دستورها میتوانند قوانینی که رباتها باید از آنها پیروی کنند را تعریف کنند.
در هر فایل robots معمولا ۵ دستور وجود دارد.
- User-agent: مشخص میکند این قانون برای کدام ربات اعمال شود (مثلاً Googlebot، Bingbot یا همه رباتها).
- Disallow: از دسترسی کرالرها به فایلها، صفحات یا دایرکتوریهای خاص جلوگیری میکند. برای هر URL فقط یک خط «Disallow:» مجاز است.
- Allow: بر خلاف دستور Disallow عمل میکند و اجازه دسترسی به یک صفحه یا منبع خاصی که Disallow شده است، را میدهد.
- Crawl-delay: با ایجاد فاصله زمانی بین درخواستها، تعداد دفعات دسترسی رباتها به سرور را کنترل میکند.
- Sitemap: محل نقشه سایت را به خزندهها معرفی میکند تا فرآیند کرال و ایندکس بهتر انجام شود.
قالب اصلی نوشتن دستور به رباتها در فایل robots.txt:
User-agent: [user-agent name]
Disallow: [آدرس صفحه یا فولدری که نمیخواهید توسط رباتها بررسی شود]
هر فایل robots میتواند شامل چندین خط user agent و دستورالعمل باشد (دستوراتی مثل disallows, allows, crawl-delays و…).
در ادامه وظیفه هر کدام از دستورهای فایل robots.txt را دقیقتر بررسی کردهایم.
دستور User-agent
دستور User-agent باید اولین خط در هر گروه قانون باشد. زیرا نام رباتی که قرار است از دستورالعملها پیروی کند را مشخص میکند. از این دستور به دو شکل در فایل robots.txt استفاده میشود:
استفاده از علامت ستاره یا «*» بهعنوان نام user-agent بهمعنای اعمال قانون برای تمام خزندهها است. مثال:
User-agent:*
اما اگر قصد دارید دستورهای موجود را فقط برای یک ربات خاص اعمال کنید باید نام ربات را بهصورت کامل و دقیق بنویسید. مثال:
User-agent: Googlebot
دستور Disallow
این دستور به رباتها میگوید که چه بخشهایی از سایت را نباید کرال کنند. اگر قانون برای یک صفحه خاص باشد، باید آدرس کامل صفحه (مانند آنچه در مرورگر نمایش داده میشود) نوشته شود. این آدرس باید با کاراکتر / شروع شود و اگر به یک پوشه اشاره دارد، باید با کاراکتر / پایان یابد.
Disallow: /private/
Disallow: /admin.html
بهعنوان مثال اگر نمیخواهید موتورهای جستجو، ویدیوهای موجود در سایتتان را ایندکس کنند، همه این ویدیوها را درون یک فولدر (با نام فرضی videos) در هاستینگ خود قرار دهید و با استفاده از دستور زیر مانع از دسترسی رباتها به فولدر شوید.
User-agent:*
Disallow: /videos
دستور Allow
این دستور مشخص میکند که کدام دایرکتوری یا صفحه میتواند توسط کرالر مورد نظر بررسی شود. این قانون معمولاً برای لغو یک دستور Disallow و اجازهدادن به کرال یک پوشه یا صفحه خاص در یک مسیر مسدود شده به کار میرود.
ربات گول نسبت به سایر رباتها درک بیشتری دارد و میتواند دستور Allow را هم بررسی کند. این دستور به ربات گوگل میگوید که اجازه مشاهده یک فایل، در فولدری که Disallowed شده را دارد.
طبق مثال قبل، تصور کنید یک فایل به اسم X.mp4 در پوشه videos وجود دارد که میخواهیم ربات آن را ایندکس کند. در واقع میخواهیم این فایل را مستثنی کنیم. برای این کار، دستور زیر را مینویسیم:
User-agent:*
Disallow: /videos
Allow: /videos/X.mp4
دستور crawl-delay
در حالی که دستور crawl-delay یکی از دستورات متداول در فایل robots.txt است، Googlebot این دستور را نادیده میگیرد و از آن پشتیبانی نمیکند.
با این حال، برخی از موتورهای جستجوی دیگر (مانند Bing و Yandex) این دستور را قبول دارند و از آن برای کنترل فاصله زمانی بین درخواستهای خزنده استفاده میکنند تا فشار کمتری به سرور وارد شود.
اگر میخواهید نرخ خزش خزنده گوگل را کنترل کنید، باید از طریق Google Search Console اقدام کنید (در قسمت تنظیمات Crawl rate).
نمونه استفاده از دستور crawl-delay:
User-agent: Bingbot
Crawl-delay: 10
دستور Sitemap
آدرس sitemap باید بهصورت یک URL کامل و معتبر باشد؛ زیرا گوگل بهصورت خودکار نسخههای مختلف مانند http/https یا www/non-www را در نظر نمیگیرد یا بررسی نمیکند.
نقشههای سایت روشی مؤثر برای معرفی محتوایی هستند که میخواهید گوگل آنها را بیشتر و بهتر خزش کند، نه صرفاً اینکه مجاز به خزش آنها باشد یا نباشد.
نحوه نوشتن کامنت در فایل robots.txt
در فایل robots.txt میتوانید برای مستندسازی یا توضیح قوانین، کامنت (توضیحاتی که توسط موتورهای جستجو نادیده گرفته میشوند) اضافه کنید. برای نوشتن کامنت، کافیست در ابتدای خط علامت # قرار دهید. هر متنی که پس از این علامت بیاید، صرفاً برای انسانها خواناست و توسط رباتهای خزنده نادیده گرفته میشود.
- میتوانید کامنتها را در هر بخشی از فایل قرار دهید (قبل یا بعد از دستورالعملها).
- بهتر است کامنتها را برای مستندسازی هدف هر دستور استفاده کنید، تا در آینده خودتان یا اعضای تیم راحتتر متوجه دلیل تنظیمات شوید.
- اگر متنی که مینویسید با # شروع نشود، بهعنوان بخشی از قوانین تلقی شده و ممکن است خطا ایجاد کند.
مثال
# این دستورالعمل تمام خزندهها را از دسترسی به پوشه ادمین منع میکند
User-agent: *
Disallow: /admin/
دستورات کاربردی فایل robots.txt
در اینجا چند دستور کاربردی و رایج در فایل robots.txt ارائه شده است.
- جلوگیری از خزیدن کل سایت
توجه داشته باشید که در برخی موارد، ممکن است URLهای سایت حتی بدون خزیدهشدن، ایندکس شوند.
User-agent: *
Disallow: /
- جلوگیری از خزیدن یک پوشه و محتوای آن
برای جلوگیری از خزیدن یک پوشه کامل، یک اسلش (/) به انتهای نام پوشه اضافه کنید.
به خاطر داشته باشید که از robots.txt برای مسدودکردن دسترسی به محتوای خصوصی استفاده نکنید؛ در عوض از احراز هویت مناسب استفاده کنید. URLهایی که توسط فایل robots.txt مسدود شدهاند ممکن است بدون خزیدهشدن ایندکس شوند و فایل robots.txt میتواند توسط هر کسی مشاهده شود، که ممکن است مکان محتوای خصوصی شما را فاش کند.
User-agent: *
Disallow: /calendar/
Disallow: /junk/
Disallow: /books/fiction/contemporary/
- اجازه دسترسی به یک ربات خاص
فقط googlebot-news میتواند کل سایت را خزیش کند.
User-agent: Googlebot-news
Allow: /
User-agent: *
Disallow: /
- اجازه دسترسی به همه به جز یک خزنده خاص
Unnecessarybot نمیتواند سایت را خزش کند؛ اما سایر رباتها میتوانند.
User-agent: Unnecessarybot
Disallow: /
User-agent: *
Allow: /
- جلوگیری از خزیدن یک صفحه وب خاص
برای مثال، جلوگیری از خزیدن صفحه useless_file.html واقع در https://example.com/useless_file.html و other_useless_file.html در پوشه junk.
User-agent: *
Disallow: /useless_file.html
Disallow: /junk/other_useless_file.html
- جلوگیری از خزیدن کل سایت به جز یک زیرپوشه
خزندهها فقط میتوانند به زیرپوشه public دسترسی داشته باشند.
User-agent: *
Disallow: /
Allow: /public/
- مسدود کردن یک تصویر خاص از Google Images
برای مثال، جلوگیری از خزیدن تصویر dogs.jpg.
User-agent: Googlebot-Image
Disallow: /images/dogs.jpg
- مسدود کردن تمام تصاویر سایت از Google Images
گوگل نمیتواند تصاویر و ویدیوها را بدون خزیدن آنها ایندکس کند.
User-agent: Googlebot-Image
Disallow: /
- جلوگیری از خزیدن فایلهای با نوع خاص
برای مثال، جلوگیری از خزیدن تمام فایلهای .gif.
User-agent: Googlebot
Disallow: /*.gif$
- جلوگیری از خزیدن کل سایت، اما اجازه به Mediapartners-Google
این پیادهسازی صفحات شما را از نتایج جستجو پنهان میکند، اما خزنده وب Mediapartners-Google هنوز میتواند آنها را تحلیل کند تا تصمیم بگیرد چه تبلیغاتی به بازدیدکنندگان سایت شما نشان دهد.
User-agent: *
Disallow: /
User-agent: Mediapartners-Google
Allow: /
استفاده از کاراکترهای * و $ برای تطبیق URLهایی که با رشته خاصی پایان مییابند
برای مثال، جلوگیری از خزیدن تمام فایلهای .xls.
User-agent: Googlebot
Disallow: /*.xls$
چگونه مسدود بودن یا نبودن آدرسها توسط robots.txt برای خزندههای گوگل را تست کنیم؟
برای بررسی اینکه آیا یک آدرس توسط فایل robots.txt برای خزندههای گوگل مسدود شده یا نه، میتوانید از ابزار بازرسی URL یا URL Inspection Tool در Google Search Console استفاده کنید. این ابزار به شما نشان میدهد که آیا گوگل توانسته آن آدرس را کرال کند یا خیر و اگر محدودیتی وجود داشته باشد، دلیل آن (از جمله robots.txt) را مشخص میکند.
اگر توسعهدهنده هستید، میتوانید از کتابخانه متنباز robots.txt گوگل استفاده کنید؛ این همان کتابخانهای است که در سیستم جستجوی گوگل نیز استفاده میشود. با این ابزار میتوانید فایلهای robots.txt را بهصورت محلی روی کامپیوتر خود آزمایش و اعتبارسنجی کنید. این روش بهویژه برای تست فایلهای robots.txt پیش از انتشار روی سرور بسیار مفید است.
چگونه بفهمیم کدام فایل robots.txt روی آدرس یک صفحه یا تصویر اثر میگذارد؟
برای اینکه بفهمید کدام فایل robots.txt روی آدرس یک صفحه یا تصویر تاثیر دارد، مراحل زیر را انجام دهید.
- URL دقیق صفحه یا تصویر را پیدا کنید.
در مرورگر Google Chrome روی تصویر کلیک راست کنید و گزینه Copy image URL را انتخاب کنید. - بعد از آدرس دامنه /robots.txt را اضافه کنید.
بهعنوان مثال، فایل robots.txt برای آدرس https://images.example.com/flowers/daffodil.png میشود:
https://images.example.com/robots.txt - URL فایل robots.txt را در مرورگر باز کنید تا مطمئن شوید که وجود دارد.
اگر مرورگر نتواند فایل را باز کند، یعنی این فایل در آن مسیر وجود ندارد.
robots.txt در کجای یک سایت قرار میگیرد؟
پیدا کردن فایل robots.txt کار چندان سختی نیست. فقط کافیست آدرس اصلی سایت خود (یا هر سایت دیگری) را بنویسید و به انتهای آن یک robots.txt/ قرار دهید. به این شکل:
triboon.net/robots.txt
از اینجا میتوانید جزییات فایل robots.txt هر سایتی را به راحتی مشاهده کنید. اگر میخواهید برای ادیت فایل robots.txt سایت خودتان اقدام کنید، این فایل در قسمت Root سایت شما قرار دارد. با ورود به این بخش میتوانید فایل robots خودتان را پیدا کنید و دستورات جدیدی به آن اضافه یا دستورات قبلی را حذف کرده و سپس فایل را ذخیره کنید.
چرا به robots.txt نیاز دارید؟
فایل robots.txt دسترسی رباتهای خزنده به مناطق خاصی از سایت شما را کنترل میکنند. اگر به طور تصادفی اجازه ندهید Googlebot یا همان ربات گوگل به جستجوی کل سایت شما بپردازد، ممکن است به سایتتان آسیب برسد. شرایطی وجود دارد که یک فایل robots.txt میتواند برای سایت شما بسیار مفید عمل کند. برخی موارد استفاده معمول از فایل robots.txt به شرح زیر است:
- جلوگیری از نمایش محتوای تکراری در SERP (به این نکته توجه داشته باشید که رباتهای متا معمولا گزینه بهتری برای این کار هستند).
- خصوصی نگه داشتن بخشهایی از یک سایت که نمیخواهید گوگل آن را ببیند یا ایندکس کند.
- جلوگیری از نمایش صفحات نتایج جستجوی داخلی در یک SERP عمومی
- تعیین محل نقشه سایت
- جلوگیری از ایندکسشدن برخی فایلهای خاص در سایت (تصاویر، PDF و…) توسط موتورهای جستجو
- تعیین تاخیر خزش یا crawl delay به منظور جلوگیری از بار اضافی سرورهای شما هنگام کرال شدن همزمان چندین محتوا
بهترین روشهای SEO برای فایل robots.txt
- مطمئن شوید هیچ محتوا یا بخشی از سایت خود را که میخواهید کرال شود، مسدود نکرده باشید.
- لینکهای صفحات مسدود شده توسط txt دنبال نمیشوند؛ مگر اینکه از سایر صفحات قابل دسترسی به موتور جستجو لینک داده شوند که در این صورت لینکهای منبع کرال نخواهند شد و ممکن است ایندکس نشوند.
- برای جلوگیری از نمایش دادههای حساس (مانند اطلاعات خصوص کاربر) در نتایج SERP از txt استفاده نکنید. با وجود دستور Disallow هنوز ممکن است گوگل صفحه شما را ایندکس کند. اگر میخواهید خیالتان برای ایندکس نشدن یک صفحه در گوگل راحت شود، از روش دیگری مانند رمز عبور محافظت شده یا دستورالعمل متنی noindex استفاده کنید.
- بعضی از موتورهای جستجو چندین user-agents دارند. مثلا گوگل از Googlebot برای جستجوی ارگانیک و از Googlebot-Image برای جستجوی تصویر استفاده میکند. اکثر رباتهای یک موتور جستجو از قوانین یکسانی پیروی میکنند، بنابراین نیازی به تعیین دستورالعملهای مختلف برای رباتهای متعدد یک موتور جستجو نیست، اما داشتن توانایی انجام این کار به شما امکان میدهد نحوه کرال شدن محتوای سایت خود را به خوبی تنظیم کنید.
- یک موتور جستجو، محتوای txt را کش میکند، اما معمولا حداقل یک بار در روز محتوای ذخیره شده را به روز خواهد کرد. اگر فایل را تغییر دهید و بخواهید سریعتر آن را به روز کنید، میتوانید آدرس robots.txt خود را در گوگل Submit کنید.
سخن پایانی
در دنیای سئو، جزئیات فنی مانند فایل robots.txt میتوانند نقش تعیینکنندهای در دیدهشدن یا نشدن یک سایت داشته باشند. هرچند این فایل فقط چند خط ساده است، اما میتواند مسیر خزیدن موتورهای جستجو را بهدرستی هدایت کند یا در صورت تنظیم نادرست، باعث از دست رفتن بخش مهمی از ترافیک ارگانیک سایت شود.
درک دقیق تفاوت میان دستورهای Allow، Disallow و سایر قوانین این فایل، به شما کمک میکند کنترل بیشتری بر نحوه ایندکسشدن محتوایتان داشته باشید. بهویژه در سایتهای بزرگ، استفاده هوشمندانه از robots.txt میتواند بهرهوری کرال و سرعت ایندکسشدن صفحات کلیدی را به شکل محسوسی بهبود دهد.
اگر تا امروز robots.txt را فقط یک فایل جانبی میدیدید، حالا زمان آن رسیده که به آن بهعنوان یکی از ابزارهای استراتژیک مدیریت سئو نگاه کنید. تنظیم آگاهانه این فایل، قدمی مهم در مسیر بهینهسازی فنی سایت شماست.