اگر میخواهید در نتایج جستجوی گوگل دیده شوید، ابتدا باید مطمئن باشید که سایتتان توسط گوگل خزش (Crawl) و سپس ایندکس (Index) شده است. این یعنی رباتهای گوگل (یا همان Googlebot) باید به صفحات شما دسترسی پیدا کنند، آنها را بررسی کنند و در صورت نیاز در فهرست نتایج ذخیره کنند. اما چطور میتوان فهمید گوگل تا چه اندازه سایت شما را خزش کرده است؟ و اصلاً کدام ابزارها و روشها به شما در پایش این موضوع کمک میکنند؟
در این مطلب بررسی کردهایم که از چه راههایی میتوان میزان خزش رباتهای گوگل در سایت را بررسی کرد. چون اگر رباتها به صفحات شما نرسند یا آنها را کامل خزش نکنند، محتوای شما هرچقدر هم ارزشمند باشد، در نتایج جستجو دیده نخواهد شد. در ادامه مطلب با ما همراه باشید تا جواب سوالاتتان درباره نحوه خزش گوگل بات را پیدا کنید.
بات گوگل (Google Bot) چیست؟
Googlebot برنامه اصلی گوگل برای خزیدن صفحات سایتهاست تا محتوای آنها را شناسایی کند. هدف Googlebot بهروزرسانی پایگاه داده عظیم محتوای گوگل، یعنی ایندکس، است. هرچه این ایندکس کاملتر و بهروزتر باشد، نتایج جستجوی شما دقیقتر و مرتبطتر خواهد بود.
دو نسخه اصلی از Googlebot وجود دارد:
- Googlebot Smartphone: خزنده اصلی گوگل که سایتها را مانند کاربری که با موبایل وارد سایت شده، بررسی میکند.
- Googlebot Desktop: این نسخه از Googlebot سایتها را مانند کاربری روی دسکتاپ بررسی میکند و نسخه دسکتاپ سایت را چک میکند.
علاوه بر اینها، خزندههای تخصصیتری هم وجود دارند، مثل Googlebot Image، Googlebot Video و Googlebot News.
ربات گوگل نقش حیاتی در سئوی گوگل دارد، چون در بیشتر موارد اگر صفحات شما خزش و ایندکس نشوند، امکان نمایش آنها در نتایج موتور جستجو (SERP) وجود ندارد. فراموش نکنید اگر رتبهای نداشته باشید، ترافیک ارگانیک هم نخواهید داشت.
علاوه بر این، Googlebot بهطور منظم به سایتها سر میزند تا بررسی کند که آیا محتوایی تغییر کرده یا محتوای جدیدی اضافه شده است.
بدون Googlebot، محتوای جدید یا تغییرات صفحات قدیمی در نتایج جستجو نمایش داده نمیشود. و اگر سایت بهروز نباشد، حفظ جایگاه در نتایج جستجو سختتر خواهد بود.
ربات گوگل چگونه کار میکند؟
گوگل بات بر پایه یک الگوریتم پیشرفته طراحی شده که میتواند بهصورت خودکار عمل کند و بر اساس ساختار شبکه جهانی وب (WWW) کار میکند. میتوان شبکه جهانی وب را مانند یک شبکه بزرگ از صفحات (گرهها) و ارتباطات (هایپرلینکها) تصور کرد. هر گره با یک URL منحصربهفرد شناسایی میشود و از طریق این آدرس قابل دسترسی است. لینکهای موجود در یک صفحه ممکن است به زیرفصلهایی در همان دامنه یا منابعی در دامنههای دیگر اشاره داشته باشند. ربات گوگل توانایی شناسایی و تحلیل لینکها (لینکهای HREF) و منابع (لینکهای SRC) را دارد. الگوریتمها میتوانند مؤثرترین و سریعترین مسیر برای پیمایش کل این شبکه را برای Googlebot شناسایی کنند.
Googlebot از تکنیکهای مختلف خزش استفاده میکند. بهعنوان مثال، از روش چندرشتهای (multi-threading) برای اجرای همزمان چند فرآیند خزش بهره میبرد. علاوه بر این، گوگل از خزندههایی استفاده میکند که روی بخشهای خاصی تمرکز دارند، مانند خزش در شبکه جهانی وب از طریق دنبال کردن انواع خاصی از هایپرلینکها.
گوگل بات یا کراولرهای گوگل چگونه یک سایت را خزش و ایندکس می کنند؟
فرآیند خزش و ایندکس در گوگل، برخلاف تصور سادهای که از آن وجود دارد، یک چرخه پیچیده، الگوریتممحور و چندلایه است. گوگلباتها نهتنها یک نسخه از محتوای صفحات شما را جمعآوری میکنند، بلکه تصمیم میگیرند کدام صفحات ارزش ایندکسشدن دارند و چه زمانی باید دوباره خزش شوند.
در اولین گام، URLها وارد یک صف اولویتدار (crawl queue) میشوند. این URLها ممکن است از سایتمپ، لینکهای داخلی و خارجی یا منابعی مثل previous crawl data و APIهای مختلف گوگل استخراج شده باشند. گوگلبات برای هر URL، بسته به سابقه تغییرات، اعتبار دامنه و الگوی لینکدهی، نرخ خزش (crawl rate) و اولویت خزش (crawl priority) مشخصی در نظر میگیرد. این صف توسط سیستمهای مدیریت بار (Load Management Systems) کنترل میشود تا منابع سرور شما بیشازحد مصرف نشود.
سپس از صفحه موردنظر رندر گرفته میشود؛ یعنی تمام کدهای HTML ،CSS و JavaScript توسط سیستمهای پردازشگر گوگل اجرا و تفسیر میشود تا دقیقا همان نسخهای تولید شود که کاربر نهایی مشاهده میکند. این رندر، پایهای است برای تشخیص ساختار DOM، استخراج لینکها، ارزیابی محتوای اصلی و تشخیص عناصر غیرقابلدسترس یا بلاکشده.
در مرحله ایندکس، گوگل سیگنالهای متعددی را از صفحه استخراج میکند؛ مانند محتوای متنی، متا دیتاها، دادههای ساختیافته، ساختار URL و… سپس این دادهها در سیستم ایندکس توزیعشده گوگل ذخیره میشوند. این ایندکس بر اساس Mobile-first ساخته میشود، یعنی نسخه موبایلی صفحه معیار ارزیابی و ذخیره خواهد بود.
در نهایت، در هر چرخه خزش، گوگل بات تغییرات جدید را با نسخههای قبلی مقایسه میکند و بر اساس الگوریتمهای زمانبندی خزش مجدد (Recrawl Scheduling)، تصمیم میگیرد چه زمانی باید دوباره به آن صفحه بازگردد.
انواع گوگل باتها را بشناسید
گوگل از کراولرهای زیادی برای وظایف خاص استفاده میکند و هر خزنده، خودش را با رشته متنی متفاوتی به نام «user agent» معرفی میکند.
Googlebot بهصورت evergreen عمل میکند، به این معنا که سایتها را همانطور میبیند که کاربران در آخرین نسخه مرورگر Chrome مشاهده میکنند.
|
نام Googlebot |
کاربرد اصلی و نحوه عملکرد |
|
Googlebot Smartphone |
خزندهی اصلی گوگل برای ایندکس نسخه موبایلی صفحات
از سال ۲۰۱۹ پایه بیشتر ایندکسها شده است. |
|
Googlebot Desktop |
خزندهی نسخه دسکتاپ سایتها
در موارد خاص که محتوای نسخه دسکتاپ متفاوت باشد، فعال میشود. |
| Googlebot Image | مخصوص ایندکس و بررسی تصاویر برای نمایش در جستجوی تصویری گوگل. |
| Googlebot Video | خزندهای برای شناسایی و ایندکس ویدیوها در صفحات وب جهت نمایش در بخش ویدیوی گوگل. |
| Googlebot News | ایندکس محتوای خبری برای Google News و تب «اخبار» در نتایج جستجو. |
| Google StoreBot Mobile | بررسی عملکرد و ظاهر صفحات فروشگاه گوگل در دستگاههای موبایل. |
| Google StoreBot Desktop | مشابه نسخه موبایل، اما برای بررسی صفحات فروشگاه گوگل در دسکتاپ استفاده میشود. |
| Google-InspectionTool Mobile | ربات ابزارهای بررسی زنده گوگل (مثل URL Inspection در سرچ کنسول) برای نسخه موبایلی. |
| Google-InspectionTool Desktop | همان ابزار بررسی، اما برای نسخه دسکتاپ صفحات وب. |
| GoogleOther | ربات عمومی گوگل که برای کارهای غیراصلی خزنده اصلی (مثل تحقیق، آزمایش یا سرویسهای دیگر) استفاده میشود. |
| GoogleOther-Image | مشابه GoogleOther، اما تمرکز آن روی تصاویر است. |
| GoogleOther-Video | مشابه GoogleOther، با تمرکز بر تحلیل ویدیوها. |
| Google-CloudVertexBot | ربات مربوط به سرویس Vertex AI در Google Cloud برای تعامل با دادههای میزبانیشده روی سایتها. |
| Google-Extended | رباتی که تعیین میکند دادههای سایت شما برای آموزش مدلهای هوش مصنوعی مولد گوگل (مثل Gemini/AI) استفاده شود یا خیر، بسته به تنظیمات opt-out فایل robots.txt. |
گوگل بات روی هزاران سرور اجرا میشود. این سرورها مشخص میکنند که ربات گوگل با چه سرعتی و از کدام بخشهای یک سایت خزش کند. البته Googlebot سرعت خزش خود را کاهش میدهد تا فشار زیادی به سایت وارد نکند.
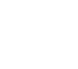
بر اساس دادههای Cloudflare Radar، گوگل بات سریعترین خزنده اینترنت است و Ahrefsbot در رتبه دوم قرار دارد.
اگر این موضوع را از نظر درصد درخواستهای HTTP بررسی کنیم، Googlebot مسئول ۲۳/۷٪ از کل درخواستهای ارسالی توسط رباتهاست.

Ahrefsbot با ۱۴/۲۷٪ در جایگاه بعدی قرار دارد. برای مقایسه، Bingbot فقط ۴.۵۷٪ و Semrushbot تنها ۰.۶٪ از این درخواستها را به خود اختصاص دادهاند.
چگونه نحوه خزش کراولرها یا باتهای گوگل را کنترل کنیم؟
راههای مختلفی برای نمایش یا مخفی کردن اطلاعات خاص از خزندههای وب وجود دارد. هر خزنده با رشتهای در فیلد «user agent» در هدر HTTP قابل شناسایی است. برای خزنده وب گوگل، این مقدار «گوگل بات» است که از آدرس میزبان googlebot.com میآید. این ورودیهای user agent در فایلهای لاگ سرور سایت ذخیره میشوند و اطلاعات دقیقی درباره اینکه چه کسی درخواستها را به سرور ارسال کرده ارائه میدهند.
شما میتوانید تصمیم بگیرید که آیا میخواهید از خزش Googlebot در سایت خود جلوگیری کنید یا نه. اگر قصد دارید Googlebot را از خزش سایتتان منع کنید، میتوانید از روشهای زیر استفاده کنید:
استفاده از دستور disallow در فایل robots.txt میتواند کل دایرکتوریهای سایت شما را از خزش خارج کند.
استفاده از تگ متای robots با مقدار nofollow در یک صفحه به Googlebot میگوید که لینکهای آن صفحه را دنبال نکند.
همچنین میتوانید از ویژگی «nofollow» برای لینکهای خاص استفاده کنید تا Googlebot فقط آن لینکها را دنبال نکند (در حالیکه سایر لینکهای همان صفحه همچنان کراول میشوند).
از کجا بفهمیم کراولرها چه میزان سایت را خزش کردهاند؟
برای اینکه بفهمیم کراولرهای گوگل (مانند Googlebot) چه میزان از سایت را خزش کردهاند، بهترین ابزار گوگل سرچ کنسول است. این ابزار اطلاعات دقیقی درباره فعالیتهای خزش و ایندکس ارائه میدهد. همچنین بررسی لاگهای سرور و آنالیز دادههای سایتمپ نیز میتواند جزئیات بیشتری در اختیار شما بگذارد.
در ادامه، روشهای مختلف برای بررسی میزان خزش سایت آورده شده است:
- Google Search Console
گزارش Crawl Stats در سرچ کنسول، آمارهایی از سابقه خزش گوگل در سایت شما نشان میدهد؛ از جمله تعداد درخواستها و زمان انجام آنها.
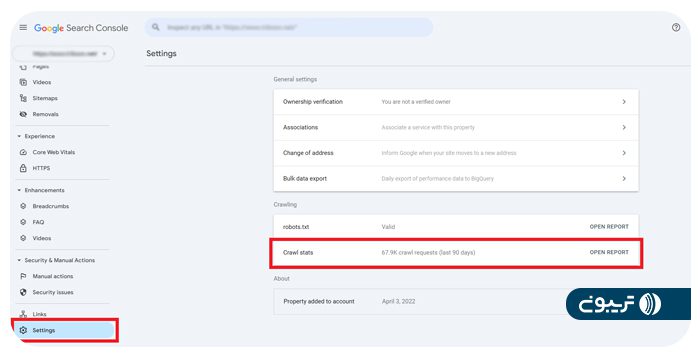
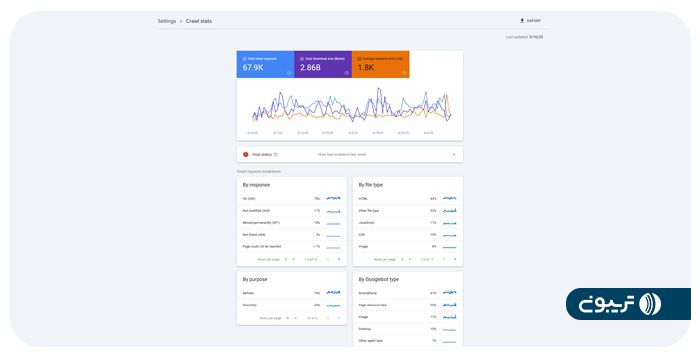
همچنین میتوانید از گزارش Pages استفاده کنید تا ببینید چند تعداد صفحه از سایت شما با موفقیت خزش و ایندکس شدهاند.
Search Console به شما کمک میکند مشکلاتی را شناسایی کنید که ممکن است مانع خزش یا ایندکس صفحات شوند.
- تحلیل لاگهای سرور
با بررسی لاگهای سرور میتوانید ببینید رباتها چند وقت یکبار به سایت شما مراجعه کردهاند، چه URLهایی را بررسی کردهاند و آیا خطایی در فرآیند خزش رخ داده است یا نه.
این روش بهویژه برای تشخیص مشکلات دسترسی به بخشهای خاصی از سایت مفید است.
- آنالیز سایتمپ
در فایل سایت مپ، بررسی تگ lastmod میتواند نشان دهد که آخرین بهروزرسانی هر صفحه چه زمانی بوده و آیا رباتها آن صفحه را بهطور منظم خزش میکنند یا خیر.
همچنین استفاده درست از سایتمپ به کشف سریعتر صفحات جدید توسط رباتها کمک میکند.
- ابزارهای آنالیز فنی سایت
ابزارهایی مانند Semrush و ابزار Moz اطلاعات دقیقی درباره صفحات خزیدهشده ارائه میدهند؛ از جمله عمق خزش (crawl depth) و کدهای وضعیت (status codes).
این ابزارها میتوانند مشکلاتی را شناسایی کنند که ممکن است مانع خزش کامل سایت توسط رباتها شوند.
- بررسی نتایج موتور جستجو
با استفاده از عملگر site:[URL] در گوگل، میتوانید تعداد تقریبی صفحاتی را که از سایت شما ایندکس شدهاند، مشاهده کنید.
این روش دید کلی و سریعی از میزان حضور سایت شما در نتایج جستجو به شما میدهد.
گوگل بات چند وقت یکبار به سایتها سر میزند؟
Googlebot برای بیشتر سایتها بهطور میانگین نباید بیشتر از یکبار در هر چند ثانیه به سایت دسترسی پیدا کند. با این حال، به دلیل تأخیرها، ممکن است نرخ خزش در بازههای زمانی کوتاه کمی بیشتر به نظر برسد. اگر سایت شما در پاسخدهی به درخواستهای خزش گوگل با مشکل مواجه شود، میتوانید نرخ خزش را کاهش دهید.
Googlebot میتواند حداکثر ۱۵ مگابایت اول از یک فایل HTML یا فایل متنی پشتیبانیشده را کراول کند. هر منبعی که در HTML ارجاع داده شده باشد (مانند CSS و JavaScript)، بهصورت جداگانه فراخوانی میشود و هر یک از این فراخوانیها نیز شامل همین محدودیت حجمی هستند. پس از رسیدن به ۱۵ مگابایت اول فایل، Googlebot خزش را متوقف میکند و فقط همان ۱۵ مگابایت اول فایل برای بررسی جهت ایندکس ارسال میشود. این محدودیت حجمی بر اساس دادههای غیرفشرده (uncompressed) اعمال میشود. سایر خزندههای گوگل، مانند Googlebot Video و Googlebot Image، ممکن است محدودیتهای متفاوتی داشته باشند.
از کجا بفهمیم یک صفحه آخرین بار کی توسط گوگل باتها، کراول شده است؟
Google Search Console این امکان را به شما میدهد که بررسی کنید بات گوگل آخرین بار چه زمانی سایت شما را خزش کرده است.
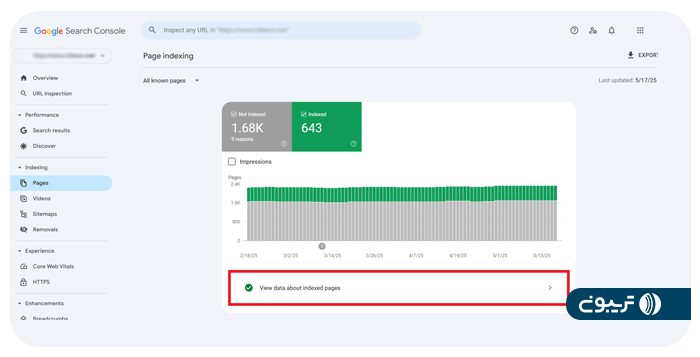
مرحله اول
وارد Google Search Console شوید و روی گزینه «pages» کلیک کنید. با این کار، نمایی کلی از خطاها یا هشدارها نمایش داده میشود. روی تب «view data about indexed pages» کلیک کنید تا تمام صفحات بدون خطا نمایش داده شوند.
مرحله دوم
حالا نمایی دقیق از صفحاتی که گوگل ایندکس کرده را مشاهده میکنید. در این جدول، برای هر صفحه تاریخی که آخرین بار گوگل آن را خزش کرده، قابل مشاهده است.
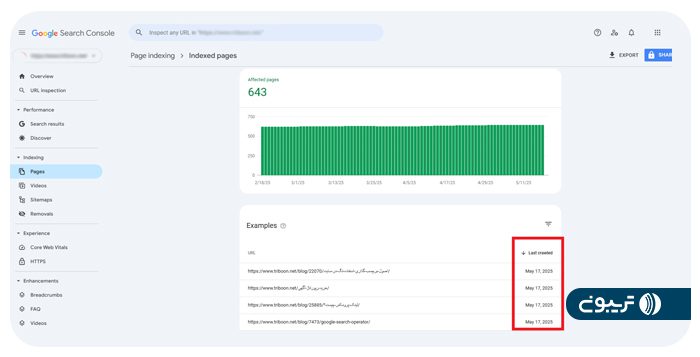
در بعضی موارد ممکن است نسخه بهروزشده یک صفحه هنوز خزش نشده باشد. در این صورت، میتوانید به گوگل اعلام کنید که محتوای آن صفحه تغییر کرده و باید مجدداً ایندکس شود. این کار را با استفاده از ابزار URL Inspection در سرچ کنسول انجام میدهید. کافیست URL موردنظر را وارد کرده و روی دکمه Request Indexing کلیک کنید.
سخن پایانی
فرآیند خزش و ایندکس گوگل یک فرآیند پیچیده و مستمر است که نیازمند مدیریت دقیق منابع و تحلیل دادههاست. گوگل با استفاده از الگوریتمهای هوشمند و استراتژیهای متنوع، تلاش میکند تا بهترین نسخه از هر صفحه وب را شناسایی و ایندکس کند، بهگونهای که هم به کاربران و هم به موتور جستجو اطلاعات دقیقی ارائه دهد. برای سئومستران و وبمستران، درک این فرآیند و بهینهسازی سایت بر اساس آن میتواند تاثیر چشمگیری در عملکرد سایت در نتایج جستجو داشته باشد. مراقبت از نحوه خزش و ایندکس صفحات و استفاده از ابزارهایی مانند Google Search Console میتواند به شما کمک کند تا عملکرد سایت خود را بهتر رصد کنید و مطمئن شوید که موتورهای جستجو اطلاعات دقیقی از سایت شما دارند.